

 今天我们在 Claude Managed Agents 中推出做梦功能作为研究预览。做梦通过审查过去的会话来发现模式并帮助 Agent 自我改进,从而扩展了记忆。我们还在向使用 Managed Agents 的开发者提供结果评估、多 Agent 编排和 Webhook。这些更新共同使 Agent 在最少引导下更能处理复杂任务。
今天我们在 Claude Managed Agents 中推出做梦功能作为研究预览。做梦通过审查过去的会话来发现模式并帮助 Agent 自我改进,从而扩展了记忆。我们还在向使用 Managed Agents 的开发者提供结果评估、多 Agent 编排和 Webhook。这些更新共同使 Agent 在最少引导下更能处理复杂任务。
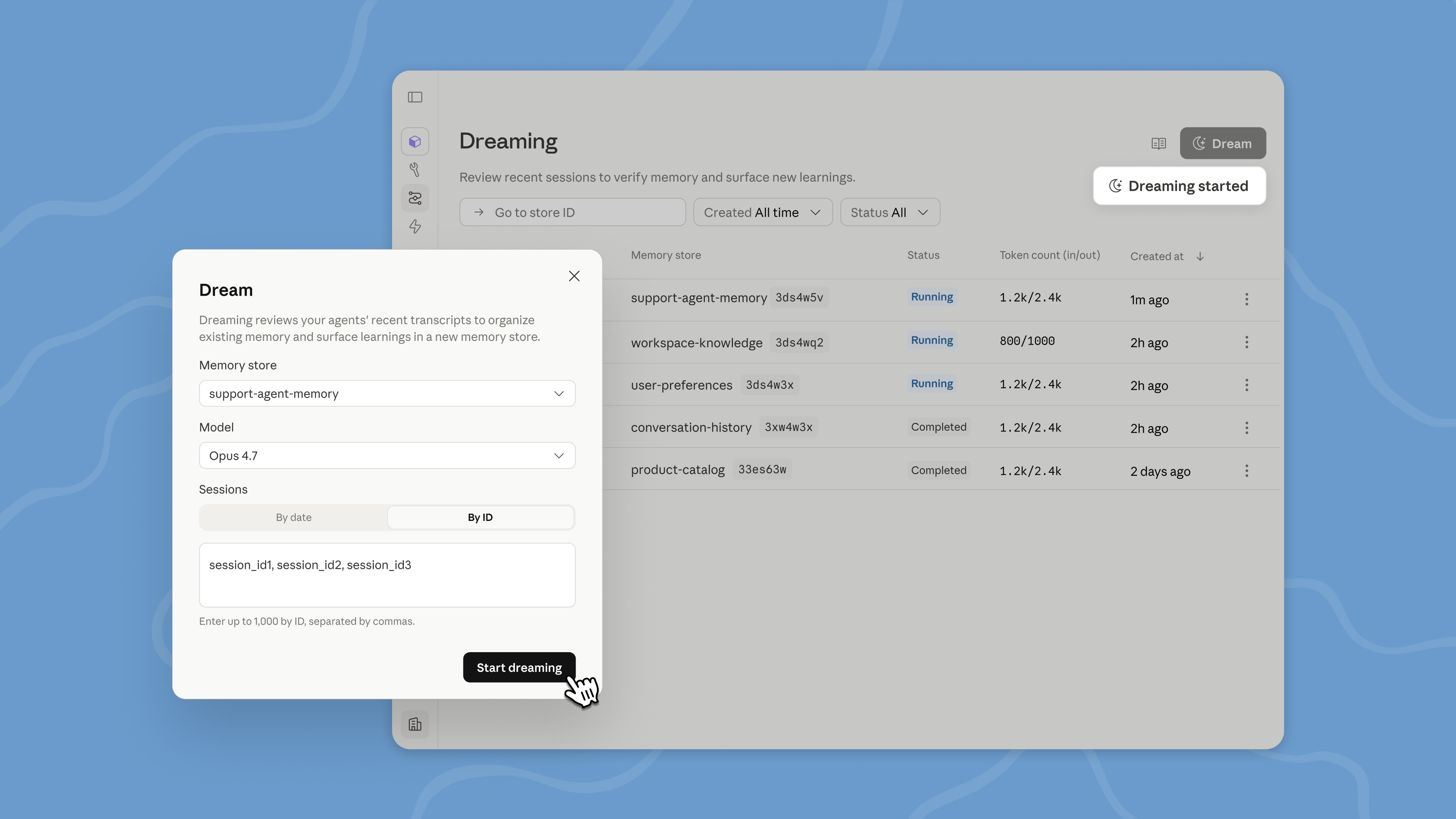
用做梦构建自我改进的 Agent
做梦是一个计划流程,审查你的 Agent 会话和记忆存储,提取模式,并整理记忆,使你的 Agent 随时间推移而改进。你决定想要多少控制:做梦可以自动更新记忆,或者你可以在更改生效之前审查它们。
做梦发现单个 Agent 自己看不到的模式,包括重复的错误、Agent 趋同的工作流,以及团队共享的偏好。
提供更好的结果
通过结果评估,你编写描述成功样子的评分标准,Agent 朝它努力。一个单独的评分器在自己的上下文窗口中根据你的标准评估输出,因此不受 Agent 推理的影响。当有问题时,评分器指出需要更改什么,Agent 再做一次。
在测试中,结果评估将任务成功率比标准提示循环提高了多达 10 个百分点,在最难的问题上获得最大的提升。
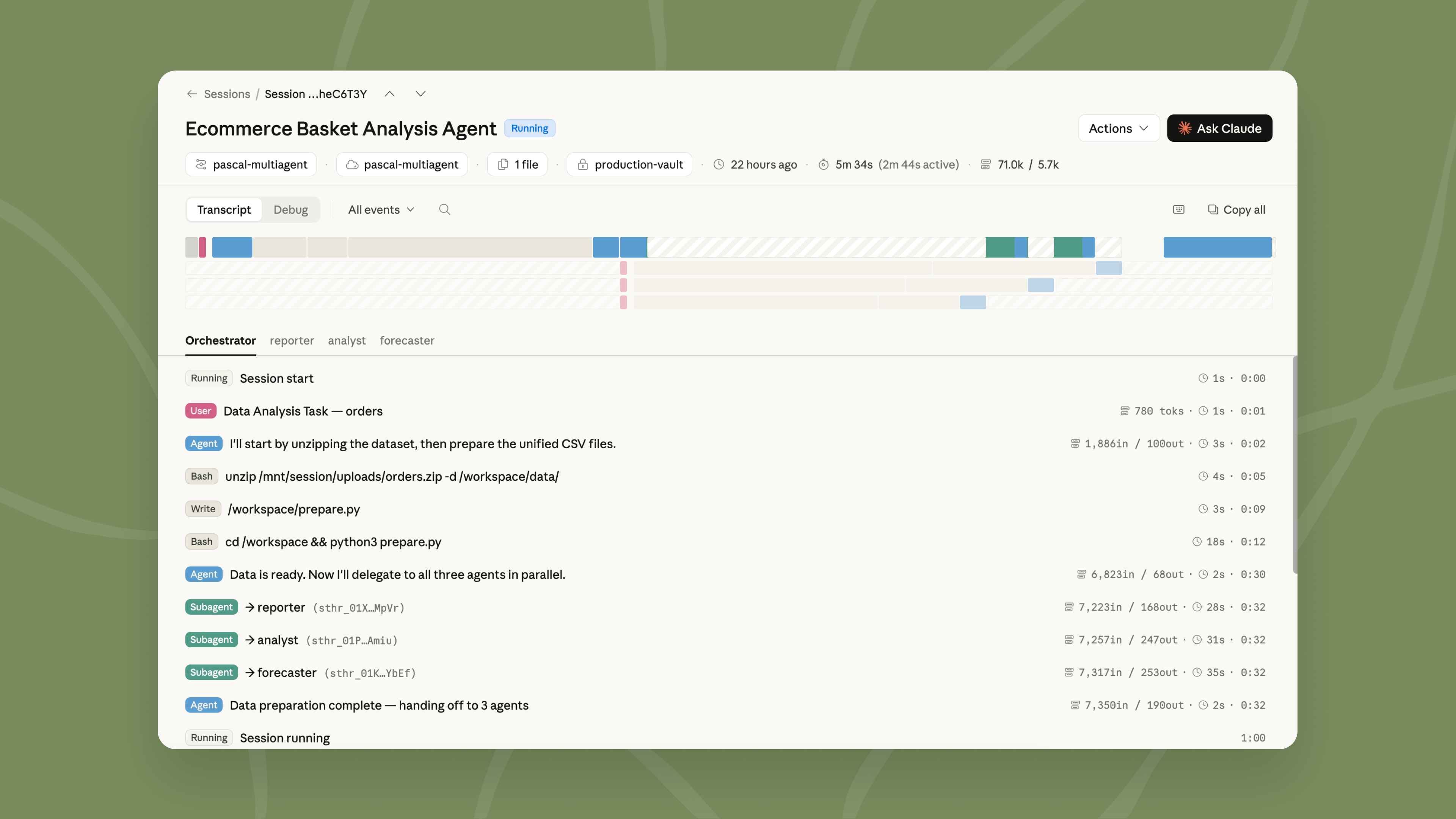
用多个 Agent 处理复杂任务
当单个 Agent 无法很好地完成太多工作时,多 Agent 编排让一个主 Agent 将工作分解为多个部分,并将每个部分委派给具有自己的模型、提示和工具的专家。
团队正在构建什么
- Harvey 使用 Managed Agents 协调复杂的法律工作。通过做梦,他们的 Agent 记住了会话之间学到的东西。完成率提高了约 6 倍。
- Netflix 平台团队构建了一个分析 Agent,使用多 Agent 编排并行分析批次并只浮现值得行动的模式。
- Spiral by Every 使用多 Agent 编排和结果评估来驱动写作 Agent。使用结果评估对照编辑原则和用户声音的评分标准来强制质量。
入门指南
做梦以研究预览版提供,结果评估、多 Agent 编排和记忆以公开测试版提供。要开始使用做梦,请在此申请访问。
评论
💬
还没有评论
欢迎留下第一条评论,帮助这篇内容更快形成讨论。